
1. Inleiding
In deze scriptie wordt de lexicale diversiteit van slechthorende kinderen vergeleken met die van horende kinderen. Er is weinig onderzoek gedaan naar eventuele verschillen in de lexicale diversiteit tussen horende en slechthorende kinderen. Wel zijn de lexicale capaciteiten van dove en slechthorende kinderen en kinderen met een cochleair implantaat onderzocht (Yoshinaga-Itano, Sedey, Coulter & Mehl, 1998; Boons, Van Wieringen, De Raeve, Peeraer & Wouters, 2011).
Lexicale diversiteit wordt door McCarthy en Jarvis (2007) omschreven als de omvang en verscheidenheid van de expressieve woordenschat. De lexicale diversiteit zou volgens een aantal onderzoekers een indicatie geven voor bijvoorbeeld schrijfvaardigheid, woordenschatkennis, algemene kenmerken van sprekerskwaliteiten en zelfs van de sociaal-economische status (Avent & Austermann, 2003; Carell & Monroe, 1993; Grela, 2002: Ransdell & Wengelin, 2003).
Een veel gebruikte maat voor het meten van lexicale diversiteit is de Type-Token Ratio (TTR, Templin 1957). De TTR wordt berekend door het aantal verschillende woorden van een taalsample (types) te delen door het totaal aantal geproduceerde woorden (tokens). Maar het bepalen van de lexicale diversiteit door het te meten met TTR is niet zonder problemen. Zo heeft Richards (1984) laten zien dat de Type-Token Ratio beïnvloed wordt door de omvang van de taalsample. Immers, wanneer de taalsample groter wordt, worden er ook steeds meer woorden herhaald, vooral de functiewoorden. De TTR neemt daardoor af en bovendien is de ideale samplegrootte om de Type-Token Ratio te berekenen niet vast te stellen.
Om de problemen met TTR op te lossen, hebben Malvern en Richards (2002) een nieuwe maat voor lexicale diversiteit ontwikkeld, namelijk D. Deze maat zou niet worden beïnvloed door de samplegrootte. Bij D kunnen alle beschikbare data gebruikt worden en daarmee is het probleem van de ideale samplegrootte opgelost.
In deze scriptie wordt de lexicale diversiteit van 20 slechthorende en 47 horende kinderen bepaald met zowel D als met de Type-Token Ratio. De kinderen zijn met elkaar gematcht op hun gemiddelde uitingslengte in woorden (MLU). Owen en Leonard (2002) hebben geconcludeerd dat D een betrouwbare maat is om de ontwikkeling van de lexicale diversiteit vast te stellen. In hun onderzoek lieten de oudere kinderen en de kinderen met een hogere MLU een hogere D-waarde zien dan de respectievelijk jongere kinderen en de kinderen met een lagere MLU. Schaerlaekens (2008) noemt dat er rond het derde levensjaar een opmerkelijke toename van de woordenschat plaatsvindt. Deze toename zou gerelateerd zijn aan de kalenderleeftijd in plaats van aan het globale taalverwervingsritme. Een simpele verklaring hiervoor zou zijn dat de leefwereld groter wordt. De fantasie- en denkontwikkeling komen in het woordgebruik tot uiting. De horende kinderen in dit onderzoek hebben een gemiddelde leeftijd onder de drie jaar; de slechthorende kinderen zijn allen ouder dan drie jaar. Dat in acht genomen, is de verwachting dat de slechthorende kinderen een grotere lexicale diversiteit laten zien dan de horende kinderen. Ondanks dat een ernstige auditieve beperking sterk de kindertaalontwikkeling beïnvloedt (Brannon & Murry, 1966; Davis, 1974; Davis, Elfenbein, Schum & Bentler, 1986). Daarbij zal gekeken worden of D en TTR een vergelijkbare mate van de lexicale diversiteit laten zien bij twee verschillende samplegroottes. Volgens McKee, Malvern en Richards (2000) is D niet beïnvloedbaar door samplegrootte. In andere zoeken is de beïnvloeding van D door samplegrootte wel vastgesteld (Owen & Leonard, 2002; Bol en Van Doornspeek, 2014). De verwachting is dat D minder beïnvloedbaar is door samplegrootte dan dat TTR dat is.
2. De taalontwikkeling van het kind
In Schaerlaekens (2008) wordt het taalverwervingsproces van jonge kinderen beschreven. Dat proces voltrekt zich tussen de leeftijd van 0 en 5 jaar. Dat wil zeggen dat de gemiddelde vijfjarige de taal kan beheersen als een volwaardig communicatiemiddel. De elementaire taalontwikkeling is rond het vijfde levensjaar afgerond, maar er zit een groot verschil tussen de manier waarop een vijfjarig kind spreekt en de manier waarop een volwassene de taal beheerst. De vervoegingen van werkwoorden zullen nog niet altijd juist zijn in de taal van het kind en daarnaast zullen zij op het gebied van taalconventies nog vaak fouten maken. Kleine kinderen hebben vaak nog niet door wanneer een bepaalde opmerking gepast is en wanneer niet. Het eindpunt van de taalontwikkeling, waaronder men kan verstaan dat het kind correct spreekt volgens de regels van de moedertaal zoals een doorsnee volwassene die beheerst, wordt eerder gesitueerd rond het negende of tiende levensjaar. Dit betekent niet het absolute eindpunt voor de taalontwikkeling; elk ouder kind en zelfs elke volwassene leert nog geregeld nieuwe woorden.
Bij taalverwervende kinderen zijn er twee taalaspecten te onderscheiden: de passieve taalontwikkeling en de actieve taalontwikkeling. Onder het eerste verstaat men het leren begrijpen, ook wel de receptieve taalontwikkeling genoemd. Onder het tweede verstaat men het praten zelf, ook wel de taalproductie genoemd. In dit onderzoek wordt ingegaan op het tweede aspect: de actieve taalontwikkeling.
Perioden en fasen
Uit crosslinguïstisch onderzoek is gebleken dat er een aantal rudimentaire evolutiepunten in de taalontwikkeling taaluniverseel is. Dit is ook bevestigd voor het Nederlands. Hierna wordt een summiere opsomming gegeven van deze punten.
Zo kent men de prelinguale periode (0-1;0 jaar), waarin het kind wel geluiden maakt en daarmee communiceert, maar nog geen echte woorden kent. Deze periode wordt gevold door een vroeglinguale periode (1;0-2;6 jaar). In deze periode gebruikt het kind woordjes en deze woordjes kunnen samengevoegd worden tot telegramstijlachtige zinnetjes. Gedurende de differentiatiefase (2;6 – 5;0 jaar) worden deze zinnen en het gehele taalgebruik vollediger en correcter. In de voltooiingsfase (5;0- 10;0 jaar) werkt het kind zijn taal verder af en voegt het lezen en schrijven eraan toe.
Lexicale ontwikkeling
Gemiddeld gebruiken Nederlandstalige kinderen vijftig woorden actief op de leeftijd van 1 jaar en 9 maanden (Schlichting, 1996). Als gemiddelde leeftijd geeft de klassieke studie van Nelson een leeftijd van 1 jaar en 7 maanden, met een spreiding van 15 tot 24 maanden (Nelson, 1973). Met betrekking tot de snelheid van de actieve woordenschat zijn er tussen kinderen dus grote verschillen. Sommige kinderen zijn erg intensief bezig met de verwerving van de eerste tien woordjes; bij andere kinderen gaat de verwerving geleidelijker. Hoe dan ook verloopt de verwerving van de eerste vijftig woorden stapsgewijs. Vaak kunnen de ouders in die periode precies vertellen welke woorden hun kinderen kunnen zeggen. Na de verwerving van de eerste vijftig woorden is er sprake van een soort woordenschatspurt. Wanneer deze spurt is ingezet, gebruikt het kind voortdurend nieuwe woordjes. Zink & Lejaegere (2002) bevonden voor het Nederlands dat tweejarige meisjes gemiddeld 292 woorden produceerden en jongens 220. De spreiding is in hun onderzoek zeer groot: van 30 tot 627 woorden. In veel andere onderzoeken wordt zo’n spreiding gevonden. In deze fase bestaat de woordenschat vooral uit zelfstandig naamwoorden, een klein aantal werkwoorden en weinig functiewoorden (Nelson, 1973; Clark, 2006).
Rond het derde levensjaar vindt een opmerkelijke toename van de woordenschat plaats. Deze toename zou gerelateerd zijn aan de kalenderleeftijd in plaats van aan het globale taalverwervingsritme. Een simpele verklaring hiervoor zou zijn dat de leefwereld groter wordt. De fantasie- en denkontwikkeling komen in het woordgebruik tot uiting
Zinslengte en woordvolgorde
Tussen het tweede en het vierde levensjaar neemt de gemiddelde zinslengte toe: voor tweejarigen is de gemiddelde uitingslengte twee woorden, voor driejarigen drieënhalf en voor vierjarigen vierenhalf woord. Na het vierde levensjaar kan de uitingslengte sterk verschillen; er is dan geen uniforme toename meer (Bol & Kuiken, 1988).
Alleen in de vroegste stadia is de MLU (Mean Length of Utterance; de gemiddelde uitingslengte) een maat die iets zegt over de syntactische complexiteit van de zin. Boven een MLU van vijf eenheden neemt men aan dat de maat niet meer indicatief is voor de syntactische complexiteit (Chabon, KentUdolf & Egolf, 1982; Crystal, 1974).
In de differentiatiefase leren kinderen om werkwoorden te vervoegen. In de vroeglinguale fase worden vooral infinite vormen van het werkwoord gebruikt. Deze ontwikkeling gaat samen met het verwerven van de persoonlijke voornaamwoorden en de flexiemorfologie (meervouden, verkleinwoorden). Vanaf de leeftijd van drie jaar geven kinderen het werkwoord een vaste plaats in de zin, waarvan de positie in de regel overeenkomt met het volwassentaalgebruik. De kindertaal kent dan niet meer het telegramstijleffect (Bol & Kuiken, 1987).
Tussen de drie en vijf jaar zal de woordvolgorde geleidelijk aan gaan lijken op het volwassentaalgebruik. Zinnen bestaan niet alleen meer uit een naamwoordelijk en een werkwoordelijk deel, maar worden dikwijls aangevuld met een lijdend en/of meewerkend voorwerp of een bepaling van plaats en tijd. Vraagzinnen-, ontkennende en samengestelde zinnen worden steeds vollediger gevormd.
Vijf à zesjarigen beschikken in het algemeen al over een behoorlijke basiswoordenschat. Hun actieve woordenschat wordt tussen de 2600 en 4000 woorden geschat (Aitchison, 2003; August, 1978).
3. Lexicale diversiteit
De lexicale diversiteit wordt door McCarthy en Jarvis (2007) omschreven als de omvang en verscheidenheid van de expressieve woordenschat. Lexicale diversiteit is een belangrijke indicator voor de actieve woordenschat en de algemene taalontwikkeling van een kind (Malvern & Richards, 2002).
Voor het meten van de lexicale diversiteit is de meest gebruikte maat de Type-Token Ratio (TTR, Templin 1957). De berekening van de TTR bestaat uit een simpele deling: het aantal verschillende woorden van een taalsample (types) wordt gedeeld door het totaal aantal geproduceerde woorden (tokens). Templin heeft in een onderzoek aangetoond dat zowel het totale aantal types als tokens stijgt met de leeftijd. De verhouding tussen types en tokens blijven bij alle kinderen nagenoeg gelijk (1:2). Het opmerkelijke was dat die verhouding niet steeg tussen de drie en acht jaar, omdat Templin over het hoofd zag dat het aantal tokens sneller steeg dan het aantal types.
Het bepalen van de lexicale diversiteit door het te meten met TTR is niet zonder problemen. Zo heeft Richards (1987) laten zien dat de Type-Token Ratio beïnvloed wordt door de omvang van de taalsample. De taalsamples varieerden van 10 tot 400 tokens. Het is gebleken dat de TTR afneemt naarmate de taalsample groter wordt. Woorden, vooral de functiewoorden, worden steeds meer herhaald. Bovendien is de ideale samplegrootte om de Type-Token Ratio te berekenen niet vast te stellen.
Om de problemen met TTR op te lossen, hebben Malvern en Richards (2002) een nieuwe maat voor lexicale diversiteit ontwikkeld, namelijk D. Deze maat zou niet worden beïnvloed door de samplegrootte. Bij D kunnen alle beschikbare data gebruikt worden en daarmee is het probleem van de ideale samplegrootte opgelost.
D als maat voor lexicale diversiteit
Owen en Leonard (2002) geven uitleg over de manier waarop D toegepast kan worden in onderzoek en in de klinische praktijk. De aanpak van de berekening van D is gebaseerd op de waarschijnlijkheid van het introduceren van nieuw vocabulair op steeds langer wordende taalsamples. D gebruikt de herhaalde berekening van TTR over een reeks van tokens om te laten zien hoe de TTR verandert in relatie tot de samplegrootte. Deze relatie wordt dan vergeleken met een wiskundig model van TTR en die vergelijking levert de D-score op. D is daarom een middel voor het meten van lexicale diversiteit waarbij D geen functie is van het aantal woorden in een taalsample (McKee et al., 2000). D maakt gebruik van alle beschikbare data en is informatiever dan TTR, omdat D laat zien hoe de TTR varieert over een reeks van samplegrootten.
4. Slechthorendheid
Slechthorendheid is de benaming voor iemand die geen normaal gehoor heeft, maar nog wel enkele geluiden en trillingen kan waarnemen. Als iemand een gehoorverlies heeft van minimaal 35 dB, gemeten in het beste oor, is hij slechthorend. Een gehoorapparaat of een cochleair implantaat (CI) kan slechthorende mensen helpen geluiden beter waar te nemen.
Er is veel onderzoek gedaan naar de taalontwikkeling van slechthorende kinderen en naar de invloed van een vroege identificatie van het gehoorverlies. Uit het onderzoek van Yoshinaga-Itano (1998) blijkt dat kinderen bij wie het gehoorverlies werd vastgesteld en geïntervenieerd voordat zij zes jaar oud waren, significant betere receptieve en expressieve taalvaardigheden lieten zien dan kinderen bij wie pas na zes maanden het gehoorverlies werd geïdentificeerd. De vroeg-geïdentificeerde kinderen hadden deze betere taalvaardigheden in ieder geval in de eerste drie levensjaren.
Gebaseerd op de chronologische leeftijd ligt het globale taalniveau van de slechthorende kinderen één à twee standaardafwijkingen onder de norm (Boons, Van Wieringen, De Raeve, Peeraer, & Wouters, 2011). Dit bevestigt resultaten uit de literatuur die aangeven dat de taalontwikkeling van veel slechthorende kinderen, ondanks de vroege screening en interventie, niet vergelijkbaar is met de taalontwikkeling van hun horende leeftijdsgenoten (Nikolopoulos, Dyar, Archbold & O’Donoghue, 2004). De variëteit binnen de groep slechthorende kinderen is groot, maar ondanks dat is er in het onderzoek van Boons et al. (2011) een specifiek patroon van de taalontwikkeling te vinden.
Op de subtests voor semantische en lexicale vaardigheden scoren de slechthorende kinderen binnen een standaardafwijking van het gemiddelde. Deze vaardigheden blijken, ook volgens Young en Killen (2002) en Spencer (2004), de sterkste aspecten te zijn van de taalontwikkeling van de slechthorende kinderen. Morfologie en syntaxis daarentegen blijken zwakke aspecten van die taalontwikkeling te zijn. Wanneer de kinderen taalvaardigheden en auditieve vaardigheden moeten integreren is dit een groot struikelblok. Hiervoor is naast een goede taalontwikkeling ook een goed auditief geheugen en auditieve perceptie nodig.
In het onderzoek van Boons et al. (2011) komt een aantal specifieke fouten naar voren uit de foutenanalyse binnen de zwakke taalaspecten, de morfologie en de syntaxis. Het valt op dat voornaamwoorden en lidwoorden vaker foutief gevormd worden door de SH-groep dan door de jongere kinderen, gematcht op hoorleeftijd. Boons et al. (2011) verklaren dit feit vanuit de auditieve prominentie-hypothese. Voornaamwoorden en lidwoorden worden weinig beklemtoond in een zin en het zijn kleine woorden die auditief sterk op elkaar lijken (bijvoorbeeld hij, zij, wij en de, het). De fouten die gemaakt worden in de keuze van voornaamwoorden kunnen worden gekoppeld aan het fenomeen ‘terugkaatsing’: het direct imiteren van dat wat tot het kind zelf gezegd wordt. Deze specifieke fouten zijn ook door Le Normand (2003) vermeld als kenmerken van de spontane taal bij slechthorende kinderen.
5. Methode
Herkomst van data
De spontane- taaldata zijn afkomstig van Bol en Kuiken (1990). Het zijn transcripten die opgenomen zijn in de CHILDES-database (Child Language Data Exchange System) (MacWhinney, 2000). Deze spontane- taalfragmenten zijn bij slechthorende en horende kinderen afgenomen.
Proefpersonen
De spontane- taalfragmenten zijn afkomstig van 47 horende kinderen en 20 slechthorende kinderen. De slechthorende kinderen hadden een gehoorverlies van 35 tot 80 dB. De horende en slechthorende kinderen zijn met elkaar gematcht op de gemiddelde uitingslengte (MLU), zie tabel 1.
Er zijn vier proefpersonen geëxcludeerd, onder wie drie horende kinderen en één slechthorend kind. Onverstaanbare uitingen zijn verwijderd uit de analyse. Het bleek dat er van drie kinderen voor het verwijderen of na het verwijderen van de onverstaanbare uitingen geen 200 woorden meer geanalyseerd konden worden. Eén kind week meer dan twee standaardafwijkingen af van het gemiddelde. Voor de leeftijd van het slechthorende kind had het een extreem hoge TTR- en D-score.

Analyse-methode TTR
Voor het berekenen van de Type-Token Ratio is het van belang dat de samplegrootte gelijk is. Er zijn twee berekeningen gemaakt van de TTR. Een berekening met een samplegrootte van 100 woorden en een grootte van 200 woorden.
Nadat de samples tot 100 en 200 woorden zijn gereduceerd, werden er frequentielijsten opgesteld voor elk afzonderlijk kind. In de frequentielijst staan de geproduceerde afleidingen van de lemma’s genoemd, de lemma’s zelf en de frequentie ervan. Hiervoor zijn de frequentielijsten uit CLAN (MacWhinney, 2000) en de spontane- taalfragmenten gebruikt. Woorden waarvan de betekenis niet te achterhalen was, zijn uit de lijst verwijderd. Daarnaast zijn alleen lemma’s meegeteld. Als bijvoorbeeld de woorden ‘worden’ en ‘wordt’ door het kind worden uitgesproken, tellen die als twee geproduceerde woorden (tokens), maar één verschillend woord (type). Ditzelfde geldt ook voor verkleinwoorden en meervouden. Zelfverbeteringen van woorden en zinnen na een valse start zijn in CLAN (MacWhinney, 2000) zo gecodeerd dat zij geëxcludeerd werden van de analyse.
De woordenlijsten zijn op al deze punten nagekeken, waardoor er items wegvielen. Uiteindelijk zijn de woordenlijsten weer aangevuld tot 100 en 200 woorden met de eerste woorden na afbraak in het transcript. Door het aantal verschillende woorden (types) te delen door het totaal aantal geproduceerde woorden (tokens) is de Type-Token Ratio voor ieder kind berekend.
Analyse-methode van D
Voor de berekening van D is eenzelfde methode gebruikt als die wordt beschreven in het artikel van Bol en Van Doornspeek (2014). D is berekend met het commando vocd binnen CLAN (MacWhinney, 2000). Vocd geeft als uitkomt een index van lexicale diversiteit. Het gebruikt de herhaalde berekening van TTR over een reeks van tokens om te laten zien hoe de TTR verandert in relatie tot de samplegrootte. Deze relatie wordt door de vocd-software vergeleken met de theoretische curven van TTR die aan de hand van het wiskundig model tot stand zijn gekomen. Deze vergelijking resulteert in de waarde D. D wordt geacht onafhankelijk te zijn van de samplegrootte, omdat het een aantal verschillende TTR’s tegen een verschillend aantal tokens representeert. Een hogere gemiddelde waarde van D duidt op een grotere lexicale diversiteit.
Statistische analyses
Om de onderzoeksvragen te beantwoorden, zijn er twee analyses uitgevoerd. In de eerste analyse is onderzocht of er een verschil is in de lexicale diversiteit tussen de horende kinderen en de slechthorende kinderen die gematcht zijn op MLU. De lexicale diversiteit is door middel van D en de Type-Token Ratio berekend. Er is gebruik gemaakt van een eenvoudige variantie-analyse (One-Way Anova) om beide groepen met elkaar te vergelijken.
In de tweede analyse is onderzocht of D en TTR afhankelijk zijn van samplegrootte. Er is gebruik gemaakt van een gepaarde t-toets om de gemiddelde waarden van D en TTR over taalsamples van een vast aantal woorden met elkaar te vergelijken. Bij de statistische testen wordt een α-niveau van α = 0.05 aangehouden.
Voor D en TTR is tot slot de effectgrootte berekend (Cohens d) om een uitspraak te kunnen doen over de invloed van de samplegrootte op beide maten. Cohen (1988) geeft aan dat een d-waarde van 0,2 als een klein effect wordt beschouwd, een d-waarde van 0,5 als een matig effect en een d-waarde van 0,8 als een groot effect.
6. Resultaten
Analyse 1: D en TTR over taalsamples van 100 en 200 woorden
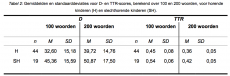
Uit de analyse blijkt dat er een significant verschil bestaat tussen de gemiddelde D100-score van de horende kinderen (H) en de slechthorende kinderen (SH) met dezelfde gemiddelde uitingslengte (One-Way Anova: F(1) = 8,90, p = 0,004), waarbij de slechthorende kinderen een hogere score hebben dan de horende kinderen. Bij de gemiddelde D200-score is er eveneens sprake van een significant verschil (One-Way Anova: F(1) = 7,07, p = 0,01). De slechthorende kinderen hebben ook hier een hogere score dan de horende kinderen. Tussen de gemiddelde TTR100-score bestaat een significant verschil (One-Way Anova: F(1) = 17,46, p < 0,0001). De scores van de slechthorende kinderen zijn hoger dan de horende kinderen. Bij de gemiddelde TTR200-score is er eveneens sprake van een significant verschil (One-Way Anova: F(1) = 19,03, p = < 0,0001). Ook hier liggen de scores van de slechthorende kinderen hoger dan de horende kinderen.
Analyse 2: invloed van samplegrootte op D en TTR
Door Malvern & Richards (2000) wordt gesteld dat D, als nieuwe maat voor lexicale diversiteit, in tegenstelling tot TTR geen relatie heeft met de samplegrootte. In deze analyse wordt gekeken of D daadwerkelijk niet beïnvloed wordt door de samplegrootte.
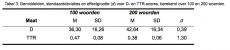
Er is een gepaarde t-toets gebruikt om de gemiddelde D100-score te vergelijken met de D200-score en de gemiddelde TTR100-score te vergelijken met de TTR200-score. Er is een significant verschil gevonden tussen de gemiddelde D100-score en de gemiddelde D200-score (gepaarde t-toets: t (61) = -5,45, p < 0,0001), inhoudend dat de D100 lager is dan de D200. Er is eveneens sprake van een significant verschil tussen de gemiddelde TTR100-score en de gemiddelde TTR200-score (gepaarde t-toets: t (61) = 16,22, p < 0,0001), inhoudend dat de TTR100 hoger is dan de TTR200. In tabel 3 zijn de gemiddelden en standaarddeviaties weergegeven.
De effectgrootte voor D is klein tot matig (Cohens d = 0,39). De effectgrootte voor TTR daarentegen is groot (Cohens d = 1,30), zie tabel 3. Voor D geldt dat er sprake is van 73% overlap en voor TTR maar een overlap van 35%.
7. Discussie
De lexicale diversiteit van horende en slechthorende kinderen is onderzocht door de D- en TTRwaarden te bepalen van hun spontane- taalsamples. Owen en Leonard (2002) hebben geconcludeerd dat D een betrouwbare maat is om de ontwikkeling van de lexicale diversiteit vast te stellen. Oudere kinderen en kinderen met een hogere MLU lieten in het onderzoek een hogere D-waarde zien dan respectievelijk de jongere kinderen en kinderen met een lagere MLU. Doordat D in staat blijkt te zijn om een ontwikkeling in lexicale diversiteit te laten zien (Owen & Leonard, 2002), is het interessant om kinderen met gehoorproblemen te vergelijken met normaal ontwikkelende kinderen, die een aantal jaren jonger zijn. In het onderhavige onderzoek is de lexicale diversiteit van slechthorende kinderen vergeleken met horende kinderen met dezelfde taalleeftijd, over taalsamples van 100 en 200 woorden. De maten D en TTR zijn hiervoor gebruikt.
De resultaten laten zien dat zowel de D-scores als de TTR-scores van de slechthorende kinderen hoger zijn dan de horende kinderen, die een lagere chronologische leeftijd hebben, maar wel dezelfde taalleeftijd. Dit komt overeen met de resultaten van Owen en Leonard (2002), waarbij de oudere kinderen een hogere D-waarde hebben, en dus een grotere lexicale diversiteit, dan de jongere kinderen. De verwachting was ook dat de slechthorende kinderen een hogere lexicale diversiteit zouden laten zien, ondanks dat een ernstige auditieve beperking een sterke invloed heeft op de jonge taalontwikkeling (Brannon & Murry, 1966; Davis, 1974; Davis, Elfenbein, Schum & Bentler, 1986). De chronologische leeftijd en daarmee de opmerkelijke spurt in de taalontwikkeling rond het derde levensjaar (Schaerlaekens, 2008) is waarschijnlijk meer bepalend voor de lexicale ontwikkeling bij slechthorende kinderen dan de taalleeftijd. Echter, om dit te kunnen concluderen zal er onderzoek gedaan moeten worden naar het verschil in lexicale diversiteit tussen slechthorende en horende kinderen die dezelfde chronologische leeftijd hebben.
Uit het onderzoek van Owen en Leonard (2002) blijkt dat er een mogelijke invloed bestaat van de samplegrootte op D, berekend over taalsamples van 250 en 500 tokens. Bol en Van Doornspeek (2014) hebben eenzelfde resultaat gevonden bij de berekening van D over taalsamples van 50 en 100 tokens. De gemiddelde D-waarde over taalsamples van 100 tokens is hoger dan de gemiddelde D-waarde over 50 tokens. Uit het onderhavige onderzoek blijkt hetzelfde. Bij de berekening van D over taalsamples van 100 en 200 woorden is er sprake van een statistisch significant verschil tussen de gemiddelde waarden van D, waarbij de gemiddelde D-waarde over taalsamples van 200 woorden hoger is dan de gemiddelde D-waarde over 100 woorden.
Dit is een enigzins verrassende uitkomst. De vocd-software gebruikt de herhaalde berekening van TTR over een reeks van tokens om te laten zien hoe de TTR verandert in relatie tot de samplegrootte. D is hierbij geen functie van het aantal woorden van de sample en wordt dus geacht onafhankelijk te zijn van de samplegrootte. McKee et al. (2000) hebben aangetoond dat er geen effect is van de samplegrootte op D. In het onderzoek van McKee et al. (2000) is D berekend over de oneven en even woorden in taalsamples van 38 kinderen. Deze D-scores zijn vergeleken met de gehele taalsamples. Uit de resultaten blijkt dat er geen statistisch significante verschillen bestaan tussen de gemiddelde Dwaarden. Doordat de oneven en even woorden uit dezelfde taalsamples zijn gebruikt, bestaat er geen verschil in gespreksonderwerp. Dit is ook in mijn onderzoek het geval, omdat de taalsamples van 100 en 200 woorden uit hetzelfde transcript komen. Bol en Van Doornspeek (2014) opperen dat het significante verschil in de gemiddelde D-waarden wellicht komt doordat er in hun onderzoek gebruik is gemaakt van de Frog Story (Mayer, 1969). In dit verhaal worden steeds meer inhoudswoorden geïntroduceerd, waardoor de kinderen naarmate het verhaal vordert meer nieuwe woorden produceren. In mijn onderzoek wordt geen gebruik gemaakt van een verhaal, maar is er sprake van spontane taal. De resultaten worden dus niet beïnvloedt door het introduceren van nieuwe woorden. Voor vervolg onderzoek zou gebruik gemaakt kunnen worden van de methode van McKee et al. (2000) door even en oneven woorden uit een taalsample te vergelijken met de gehele taalsample.
Analyses van de effectgrootte laten zien dat D wel minder beïnvloedt wordt door de omvang van de taalsample dan de meer gebruikelijke maat voor het meten van lexicale diversiteit, de Type-Token Ratio.
D en TTR zijn beide beïnvloedbaar door de samplegrootte. Echter, omdat D in mindere mate beïnvloedbaar is en veranderingen in de lexicale ontwikkeling kan aantonen (Owen & Leonard, 2000), lijkt D op dit moment de meest geschikte middel om de lexicale diversiteit van horende en slechthorende kinderen te bepalen.
Referenties
- Aitchison, J., Cappa, S. & Perani, D. (2001). The bilingual brain as revealed by functional neuroimaging, Bilingualism: Language and Cognition, 4, 179-190.
- August, G. (1978). Spracherwerb von 6 bis 16. Düsseldorf: Schwann.
- Avent, J.R. & Austermann, S. (2003). Reciprocal scaffolding: A context for communication treatment in aphasia. Aphasiology, 17, 397–404.
- Bol, G. W. & Van Doornspeek, M. (2014). Lexicale diversiteit bij eentalige en tweetalige kinderen met SLI: de maat D vergeleken met de TTR. Stem-, Spraak- en Taalpathologie, 19, 42-58.
- Bol, G. W. & Kuiken, F. (1988). Grammaticale Analyse van Taalontwikkelingsstoornissen. Proefschrift, Universiteit van Amsterdam. Bol, G. W. & Kuiken, F. (1987). The development of morphosyntax in Dutch children from one to four. Belgian Journal of Linguistics, 2, 93-108.
- Bol, G.W. & Kuiken, F. (1990). Grammatical analysis of developmental language disorders: a study of the morphosyntax of children with specific language disorders, children with hearing impairment and children with Down syndrome. Clinical Linguistics and phonetics, 4, 77-86.
- Boons, T., Van Wieringen, A., De Raeve, L., Peeraer, L. & Wouters, J. (2011). Evaluatie van de taalvaardigheid van ernstig slechthorende kinderen en dove kinderen met de CELF-4-NL. Stem-, Spraak- en Taalpathologie, 17, 52-72.
- Brannon, J.B. & Murry, T. (1966). The spoken syntax of normal, hard-of-hearing, and deaf children. Journal of Speech and Hearing Research, 9, 604–610. Carrell, P.L. & Monroe, L.B. (1993) Learning styles and composition. The Modern Language Journal, 77, 148–62.
- Chabon, S., Kent-Udolf, L. & Egolf, D. (1982). The temporal reliability of Brown’s mean length of utterance (MLU-M) measure with Post-Stage V children, Journal of Speech and Hearing Research, 25, 124-128.
- Clark, E. (2006). First Language Acquisition. Cambridge: Cambridge University Press. Cohen, J. (1988). Statistical power analysis for the behavioral sciences (2nd ed). Hillsdale, NJ: Erlbaum. Crystal, D. (1974). Review of R. Brown ‘A first language’, Journal of Child Language, 289-307.
- Davis, J. (1974). Performance of young hearing-impaired children on a test of basic concepts. Journal of Speech and Hearing Research, 17, 342–351.
- Davis, J.M., Elfenbein, J., Schum, R. & Bentler, R.A. (1986). Effects of mild and moderate hearing impairments on language, educational, and psychosocial behavior of children. Journal of Speech and Hearing Disorders, 51, 53–62.
- Grela, B.G. (2002). Lexical verb diversity in children with Down syndrome. Clinical Linguistics & Phonetics, 16, 251–63.
- Le Normand, M. T., Ouellet, C. & Cohen, H. (2003). Productivity of lexical categories in Frenchspeaking children with cochlear implants. Brain and Cognition, 53, 257-262.
- MacWhinney, B. (2000). The CHILDES Project: tools for analyzing talk. Mahwah, NJ: Lawrence Erlbaum Associates. Malvern, D.D. & Richards, B.J. (2002). Investigating accomodation in language proficiency interviews using a newmeasure of lexical diversity. Language Testing, 19, 85-104.
- Malvern, D.D. & Richards, B.J. (2000). Validation of a new measure of lexical diversity: a pilot study. In: Beers, M., Van den Bogaerde, M.B., Bol, G.W., De Jong, J. & Rooijmans, C. (Eds.). From Sound to Sentence: Studies on a First Language Acquisition. Centre for Language and Cognition Groningen, Groningen, p. 81-96.
- Mayer, M. (1969). Frog, where are you? New York, NY: Dial Books for Young Readers.
- McCarthy, P.M. & Jarvis, S. (2007). Vocd: a theoretical and empirical evaluation. Language Testing, 24, 459-488.
- McKee, G., Malvern, D. & Richards, B. (2000). Measuring vocabulary diversity using dedicated software. Literacy and Linguistic Computing, 15, 323-337.
- Nelson, K. (1973). Structure and strategy in learning to talk. Society for Research in Child Development Monograph, 38 (Serial No 149). Nikolopoulos T. P., Dyar D., Archbold S. M. & O’Donoghue G. M. (2004). Development of Spoken Language Grammar Following Cochlear Implantation in Prelingually Deaf Children. Archives of Otolaryngology and Head and Neck Surgery, 130, 629-633.
- Owen, A. J. & Leonard, L. B. (2002). Lexical Diversity in the Spontaneous Speech of Children With Specific Language Impairment: Application of D. Journal of Speech, Language, and Hearing Research, 45, 927-937.
- Ransdell, S. & Wengelin, Å. (2003). Socioeconomic and sociolinguistic predictors of children’s L2 and L1 writing quality. Arobase, 1–2, 22–29.
- Richards, B.J. (1987). Type/Token ratios: what do they really tell us? Journal of Child Language, 14, 201-209. Schaerlaekens, A.M. (2008). De taalontwikkeling van het kind. Groningen: Noordhoff Uitgevers.
- Schlichting, L. (1996). Discovering Syntax: An Empirical Study in Dutch Language Acquisition. Proefschrift, KU Nijmegen.
- Spencer P. E. (2004). Individual Differences in Language Performance after Cochlear Implantation at One to Three Years of Age: Child, Family, and Linguistic Factors. The Journal of Deaf Studies and Deaf Education, 9, 395-412.
- Templin, M. (1957). Certain language skills in children. Minneapolis, MN: University of Minneapolis Press.
- Yoshinaga-Itano, C., Sedey, A.L., Coulter, D.K. & Mehl, A.L. (1998). Language of early- and lateridentified children with hearing loss. Pediatrics, 102, 1161-1171. Young G. A. & Killen D. H. (2002). Receptive and expressive language skills of children with five years of experience using a cochlear implant. The Annals of otology, rhinology, and laryngology, 111 (9), 802-810.
- Zink, I. & Lejaegere, M. (2002). N-CDIs: Lijsten voor Communicatieve ontwikkeling -Aanpassing en hernormering van de MacArthur CDIs van Fenson et al. Leuven/Leusden: Acco.

